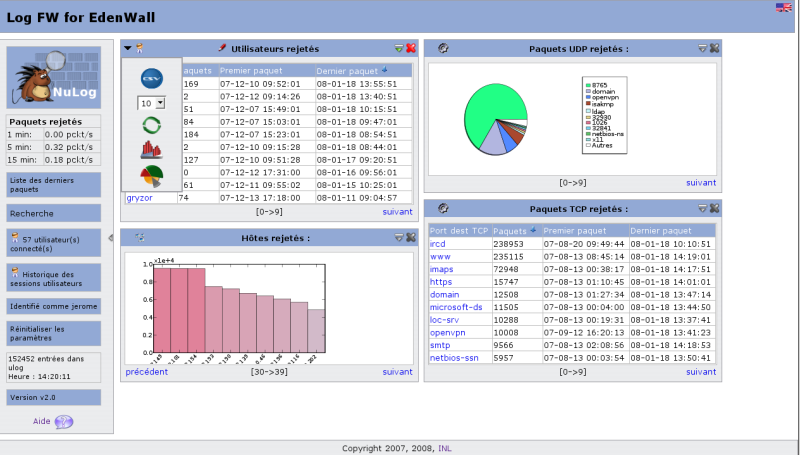
Installation
If you’ve followed the previous
article,
you now have a working ulogd2 installation.We will now explore the way
data are stored in the database, and the default SQL schema provided
with ulogd2.
SQL schema, basics
The SQL schema ? Not really, only the default one. Ulogd2 uses stored
procedures and views to create an abstraction layer between the C code
and the real storage of the data (the tables in the SQL database). The
basics are the following:
Inserting data using the “INSERT” keyword is fast, but requires the
application to know the SQL schema. An update of the SQL part will need
an update of the C code, which is not very handy. So instead of using:
INSERT INTO tablename (field1,field2,...) VALUES (1,2,...);
We will create a stored procedure (in this example, we use PostgreSQL
PL/pgSQL syntax):
CREATE OR REPLACE FUNCTION INSERT_PACKET_FULL(
IN value11 integer,
...)
RETURNS bigint AS $$
DECLARE
t_id bigint;
DECLARE
t_id := INSERT INTO tablename (field1,field2,...) VALUES ($1,$2,...);
RETURN t_id;
END
$$ LANGUAGE plpgsql SECURITY INVOKER;
Inserting data can now be done, using:
SELECT INSERT_PACKET_FULL(1,2,3,...);
So, we have succeeded into transforming a fast and single (and simple)
query into something slower and more complex, great. But why ?
Pros:
- C and SQL code independence: now we can change the SQL part without
updating the C code
- The SQL schema can be specific to the database used, and use the
specific data types. For ex., PostgreSQL provides native support for
IP and MAC addresses (using the inet and macaddr types) while
MySQL does not, so we used binary types.
- SQL schema is easy to extend for specific needs or applications: you
just need to add a new table, linked to the main table using the
unique ID of the packet. This won’t affect ulogd2.
- Retrieving data is also easier for applications (like
NuLog, since
the schema is hidden behind views (or stored procedures).
- You have a finer control on what is done with the data
Cons:
- Slower
- Harder to read
- Some databases do not have stored procedures (for ex. sqlite)
Default SQL schema (many tables)
Unlike the first version of ulogd, the default SQL schema provided with
ulogd2 splits the data from the packets into several tables, each table
containing data for a protocol. There are tables for IP (common fields
for all packets), TCP, UDP, ICMP, ICMPv6, and since recently, SCTP. MAC
addresses are also stored in a different table.
Global picture:
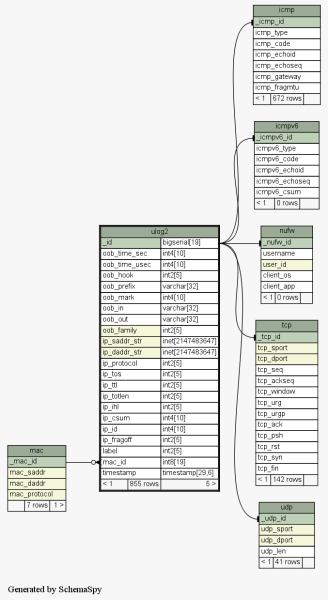
The provides a “cleaner” SQL schema than the “all-in-one-table”
from the previous version, but at the cost of performance: each new
packet will cause several insertions into different tables, and
retrieving data will require to fetch data from several tables (using
JOINs).This is, however, better space-efficient, since less data are
stored (for ex, the MAC address is stored only once, and identified by a
unique ID in the main table).
There are several views provided with this schema:
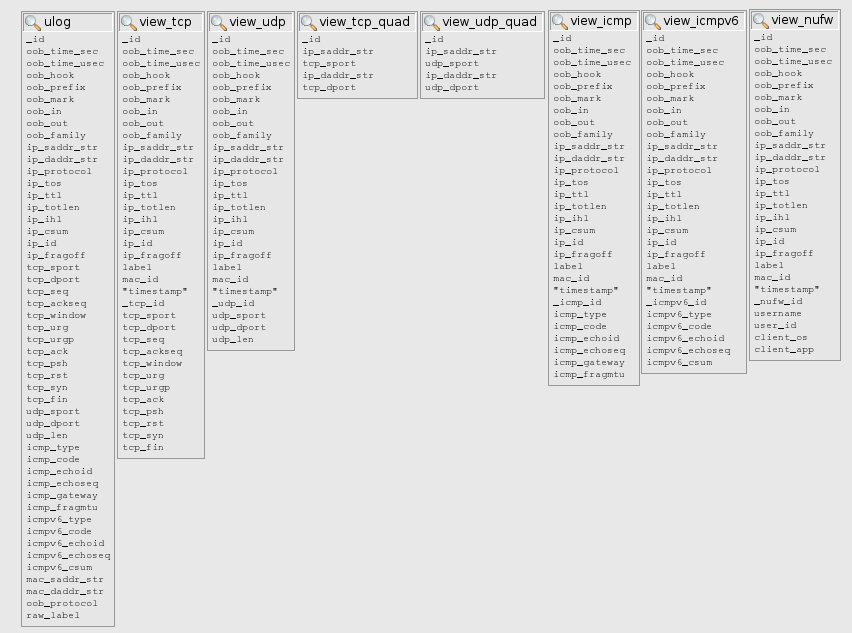
Each view is defined to fetch data from several tables:
CREATE OR REPLACE VIEW view_tcp AS
SELECT * FROM ulog2 INNER JOIN tcp ON ulog2._id = tcp._tcp_id;
Even the "big" table ulog is a view, combining data from all tables:
CREATE OR REPLACE VIEW ulog AS
SELECT _id,
oob_time_sec,
...
FROM ulog2 LEFT JOIN tcp ON ulog2._id = tcp._tcp_id LEFT JOIN udp ON ulog2._id = udp._udp_id
LEFT JOIN icmp ON ulog2._id = icmp._icmp_id
LEFT JOIN mac ON ulog2.mac_id = mac._mac_id
LEFT JOIN hwhdr ON ulog2._id = hwhdr._hw_id
LEFT JOIN icmpv6 ON ulog2._id = icmpv6._icmpv6_id;
This way, the application can quickly know, for ex, the number of
different TCP ports used for destination and the number of packets using
these ports:
SELECT tcp_dport,count(*) from view_tcp GROUP BY view_tcp.tcp_dport;
tcp_dport | count
===================
80 | 39
443 | 2
This schema should be used when your insertion rate is not too high (you
are not CPU-bound).
Flat SQL schema
The default schema will work for most installations. However, if you
have are logging data on a fast link, you may have performance problems.
Assuming the problems come from the CPU, one solution is to change the
SQL schema to a flat one (all in one table).
The flat schema is not yet written, but will shortly be submitted to ulogd2.
Please note that if the performance problem does not come from the CPU,
it is very likely to come from the disks performance, in this case you
will have to do some DB optimizations …
Supported databases
Currently supported databases are MySQL and PostgreSQL. sqlite does not
work, since it does not support stored procedures.
I have also recently submitted a new output plugin using the libdbi
database abstraction layer, which
brings support for Firebird, FreeTDS (MS-SQL and Sybase), Ingres, and
Oracle. It also supports MySQL and PostgreSQL, but there are specific
plugins for those 2.
The DBI plugin is not designed to replace all other plugins, since it
can’t use the DB-specific API, for ex the asynchronous API for
PostgreSQL.
That’s all for the database overview ! Now let’s just hope that the
(in)famous user “OR DROP DATABASE ulog; —” does not try to log
anything ;)
References