If you’ve followed the previous
article,
you now have a working ulogd2 installation.We will now explore the way
data are stored in the database, and the default SQL schema provided
with ulogd2.
SQL schema, basics
TheSQL schema ? Not really, only the default one. Ulogd2 uses stored
procedures and views to create an abstraction layer between the C code
and the real storage of the data (the tables in the SQL database). The
basics are the following:
Inserting data using the “INSERT” keyword is fast, but requires the
application to know the SQL schema. An update of the SQL part will need
an update of the C code, which is not very handy. So instead of using:
INSERT INTO tablename (field1,field2,...) VALUES (1,2,...);
We will create a stored procedure (in this example, we use PostgreSQL
PL/pgSQL syntax):
CREATE OR REPLACE FUNCTION INSERT_PACKET_FULL(
IN value11 integer,
...)
RETURNS bigint AS $$
DECLARE
t_id bigint;
DECLARE
t_id := INSERT INTO tablename (field1,field2,...) VALUES ($1,$2,...);
RETURN t_id;
END
$$ LANGUAGE plpgsql SECURITY INVOKER;
Inserting data can now be done, using:
SELECT INSERT_PACKET_FULL(1,2,3,...);
So, we have succeeded into transforming a fast and single (and simple)
query into …
Xtables-addons
is a is a project developped by Jan Engelhardt to replace the old
patch-o-matic repository for the Linux kernel and iptables. Instead of
patching the kernel source, extensions are built as modules and thus
allow extending kernels without recompilation.
I have created a Debian
package, split
in two parts: xtables-addons-source (the sources of the kernel modules),
and xtables-addons-common (common files: shared libraries, man pages, binaries).
To install xtables-addons on Debian (sid only, but the package works on
Lenny after a rebuild), run the following commands:
It will automatically install the headers for your kernel, build the
modules, create a local package, and install it. What’s interesting is
that, unlike before (using p-o-m or kernel patches), there is no need
to reboot.
It adds new targets for iptables:
CHAOS: randomly use REJECT, DELUDE or TARPIT targets. This will fool
network scanners by returning random results
DELUDE: always reply to a SYN by a SYN-ACK. This will fool TCP
half-open discovery
DHCPADDR: replace a MAC address from and to a VMware host
The next edition of the Netfilter Workshop will take place in Paris,
France, from September 29th to October 3th, 2008.
The first day is open to everyone, and the
program
is now online.
There will be many interesting presentations, and I will give a
presentation of
nfqueue-bindings
and the
weatherwall,
a firewall based on the weather of the location of the destination of
the packets, and
ulogd2
along with Eric.
Entry is free but a registration is asked. Please fill in the
registration form.
The code for nfqueue-bindings is now almost ready, I have made some
progress since last week:
you can now modify packets in live, and send the new packet with the verdict
new functions are wrapped, and the creation of the queue can be done in one function
more examples
I have presented a special script for SSTIC,
using the weather to decide if a packet should be accepted or dropped
:)While the utility of the module still has to be proven, it is a good
example of how easy it is to use the new bindings.
The slides can be found online
here,
and contains some code examples (with some funny things ;). They are in
french, but they should be quite easy to understand.
Random ideas:
The Netfilter workshop will be held in Paris from 30 September to 3 October 2008.
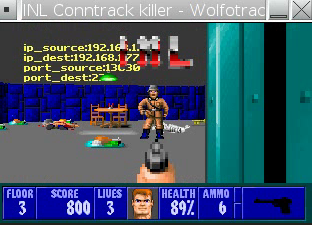
Eric has presented nf3d, a nice tool to view netfilter logs (from ulogd2) in 3D.
Gamers will recognize a nice try to convert network logs into Guitar
Hero tracks ;)
I am currently working (amongst other projects ..) on
nfqueue-bindings,
set of high-level modules for several languages (Python and Perl, for
the moment), for
libnetfilter_queue.
The goal is to provide a library to gain access to packets queued by the
kernel packet filter. For more details, see nfqueue-bindings project
site.
Current state
Actually, you can
access the module in Perl or Python
create a queue connected to netfilter
register a callback
access the contents of the packet. As I do not want to do what was already done many times, I use some other libraries to decode the packet:
A firewall has to find the difference between good and bad packets, and
for this, nothing is better than humans ! (french people could add this
is the same difference as for good and bad hunters).
So the next generation firewall will be:
better than stateful
better than layer 7 analysis
compliant with encrypted traffic
able to detect malware, suspicious traffic, virus, etc.
Preview screenshot:
Source code should be released on monday, on the Netfilter mailing
lists. Stay tuned !
This article explains how to build, install and configure ulogd
2 for use with
netfilter/iptables. It explains how to
use plugins to store logs in databases (MySQL and PostgreSQL), use
plugins to filter data, and gives some iptables rules to log packets.
Use the standard autotools method for configure, build and install:
./autogen.sh
./configure --prefix=/path/to/prefix
make
sudo make install
Configuration
Edit ulogd.conf
1. enable plugins
You will have to choose the input and output plugins according to your
setup. NFLOG is present in recent kernels (and iptables installation),
and should be preferred if possible.
Input plugin: ULOG or NFLOG
Output: MySQL or PostgreSQL
You have to enable the corresponding in the configuration before you can
use them:
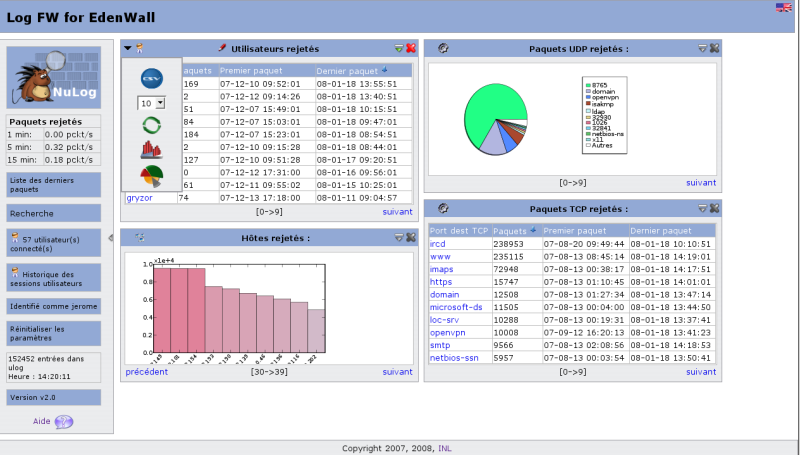
Ulogd (and also ulogd2) is a powerful and flexible logging system for
Netfilter/Iptables, based on a plugin system. It allows, for example, to
log packets in a SQL database, and have some interface to analyze it
(see Nulog2)
Architecture
Ulogd2 combines plugins to create a stack, where each plugin is chained
to another. There are three types of plugins:
Source
Filter
Output
A stack must have only one source, and one output (yet it can
have several filters). It is possible to define several stacks in
the configuration.
Each plugin has a type (for ex, PGSQL), and must be instanciated
(using a name chosen by the user). Each instance is a particular version
of the plugin, defining parameters. This way, we will be able to output
data in several formats using different stacks.